- 수업 내용 리마인드 및 아카이빙 목적의 업로드
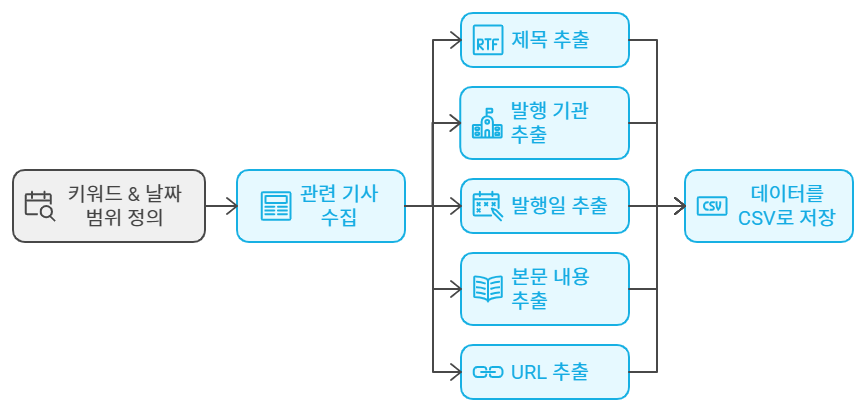
Q. 네이버 뉴스에서 '특정 키워드(청년취업사관학교)'와 '날짜 범위(20240101~20240731)'에 해당하는 게시물들을 자동으로 수집하고, 각 게시물의 "제목", "발행기관", "작성일", "본문 내용", "URL"을 추출하여 CSV 파일로 저장하는 코드를 작성하세요.
청년취업사관학교 : 네이버 뉴스검색
'청년취업사관학교'의 네이버 뉴스검색 결과입니다.
search.naver.com
A. 네이버 뉴스 데이터 수집 스크립트
전체 코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json
def clean_text(text):
return text.replace("\n", "").replace("\t", "").replace("\r", "")
def get_news_item(url):
try:
res = requests.get(url)
res.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Failed to retrieve news item: {url}, error: {e}")
return None
soup = BeautifulSoup(res.text, "html.parser")
try:
title = soup.select_one("h2#title_area").text
media = soup.select_one(".media_end_head_top_logo img")["title"]
date = soup.select_one(".media_end_head_info_datestamp_time")["data-date-time"]
content = clean_text(soup.select_one("#newsct_article").text)
return title, media, date, content, url
except AttributeError as e:
print(f"Failed to parse news item: {url}, error: {e}")
return None
def get_naver_news(keyword, startdate, enddate, to_csv=False):
ret = []
for d in pd.date_range(startdate, enddate, freq='D'):
page = 1
print(f"Processing date: {d}")
while True:
start = (page - 1) * 10 + 1
url = f"https://s.search.naver.com/p/newssearch/search.naver?de={d.strftime('%Y.%m.%d')}&ds={d.strftime('%Y.%m.%d')}&eid=&field=0&force_original=&is_dts=0&is_sug_officeid=0&mynews=0&news_office_checked=&nlu_query=&nqx_theme=&nso=%26nso%3Dso%3Add%2Cp%3Afrom{d.strftime('%Y%m%d')}to{d.strftime('%Y%m%d')}%2Ca%3Aall&nx_and_query=&nx_search_hlquery=&nx_search_query=&nx_sub_query=&office_category=0&office_section_code=0&office_type=0&pd=3&photo=0&query={keyword}&query_original=&service_area=0&sort=1&spq=0&start={start}&where=news_tab_api&nso=so:dd,p:from{d.strftime('%Y%m%d')}to{d.strftime('%Y%m%d')},a:all"
try:
res = requests.get(url)
res.raise_for_status()
res_dic = json.loads(res.text)
except requests.exceptions.RequestException as e:
print(f"Failed to retrieve search results: {url}, error: {e}")
break
except json.JSONDecodeError as e:
print(f"Failed to parse JSON: {url}, error: {e}")
break
li = res_dic.get('contents', [])
if len(li) == 0:
break
for item in li:
soup = BeautifulSoup(item, 'html.parser')
a_tags = soup.select("div.info_group a")
if len(a_tags) == 2:
news_data = get_news_item(a_tags[1]['href'])
if news_data:
ret.append(news_data)
page += 1
df = pd.DataFrame(ret, columns=["title", "media", "date", "content", "url"])
if to_csv:
df.to_csv(f"{keyword}_{startdate.replace('.','')}_{enddate.replace('.','')}.csv", index=False)
return df
get_naver_news("청년취업사관학교", "2024.01.01", "2024.07.31", to_csv=True)
코드 설명
1. 필요한 라이브러리 임포트
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json- requests: HTTP 요청을 보내 웹 페이지의 내용을 가져오는 데 사용됩니다.
- BeautifulSoup: HTML 및 XML 파일을 파싱하고 탐색하는 데 사용됩니다. 주로 웹 스크래핑에 사용되며, 이 코드에서는 네이버 뉴스 페이지의 HTML을 파싱하는 데 사용됩니다.
- pandas: 데이터 분석을 위한 라이브러리로, 데이터프레임 형태로 데이터를 저장하고 조작하는 데 사용됩니다.
- json: JSON 데이터를 파싱하는 데 사용됩니다. 이 코드는 json.loads를 사용해 서버로부터 받은 JSON 데이터를 딕셔너리로 변환합니다.
2. 텍스트 정리 함수 (clean_text)
def clean_text(text):
return text.replace("\n", "").replace("\t", "").replace("\r", "")- 문자열에서 불필요한 공백 문자(\n, \t, \r)를 제거하는 함수입니다. 뉴스 본문 내용을 깔끔하게 정리하는 데 사용됩니다.
3. 뉴스 정보 추출 함수 (get_news_item)
def get_news_item(url):
try:
res = requests.get(url)
res.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Failed to retrieve news item: {url}, error: {e}")
return None
soup = BeautifulSoup(res.text, "html.parser")
try:
title = soup.select_one("h2#title_area").text
media = soup.select_one(".media_end_head_top_logo img")["title"]
date = soup.select_one(".media_end_head_info_datestamp_time")["data-date-time"]
content = clean_text(soup.select_one("#newsct_article").text)
return title, media, date, content, url
except AttributeError as e:
print(f"Failed to parse news item: {url}, error: {e}")
return None- 주어진 뉴스 URL에서 뉴스의 제목, 매체 이름, 작성일, 본문 내용을 추출하여 튜플로 반환합니다.
- 작동 방식:
- HTTP 요청: requests.get으로 URL에 대해 GET 요청을 보내고, raise_for_status()로 요청이 성공했는지 확인합니다.
- HTML 파싱: BeautifulSoup을 사용해 페이지의 HTML을 파싱합니다.
- 데이터 추출:
- 제목: h2#title_area 요소에서 뉴스 제목을 추출합니다.
- 매체 이름: .media_end_head_top_logo img 요소의 title 속성에서 매체 이름을 추출합니다.
- 작성일: .media_end_head_info_datestamp_time 요소의 data-date-time 속성에서 작성일을 추출합니다.
- 본문 내용: #newsct_article 요소에서 본문 내용을 추출하고, 불필요한 공백을 제거합니다.
- 예외 처리: 뉴스 아이템을 가져오거나 파싱하는 과정에서 오류가 발생하면, 오류 메시지를 출력하고 None을 반환합니다.
4. 네이버 뉴스 검색 결과 가져오기 (get_naver_news)
def get_naver_news(keyword, startdate, enddate, to_csv=False):
ret = []
for d in pd.date_range(startdate, enddate, freq='D'):
page = 1
print(f"Processing date: {d}")
while True:
start = (page - 1) * 10 + 1
url = f"https://s.search.naver.com/p/newssearch/search.naver?de={d.strftime('%Y.%m.%d')}&ds={d.strftime('%Y.%m.%d')}&eid=&field=0&force_original=&is_dts=0&is_sug_officeid=0&mynews=0&news_office_checked=&nlu_query=&nqx_theme=&nso=%26nso%3Dso%3Dd d%2Cp%3Afrom{d.strftime('%Y%m%d')}to{d.strftime('%Y%m%d')}%2Ca%3Aall&nx_and_query=&nx_search_hlquery=&nx_search_query=&nx_sub_query=&office_category=0&office_section_code=0&office_type=0&pd=3&photo=0&query={keyword}&query_original=&service_area=0&sort=1&spq=0&start={start}&where=news_tab_api&nso=so:dd,p:from{d.strftime('%Y%m%d')}to{d.strftime('%Y%m%d')},a:all"
try:
res = requests.get(url)
res.raise_for_status()
res_dic = json.loads(res.text)
except requests.exceptions.RequestException as e:
print(f"Failed to retrieve search results: {url}, error: {e}")
break
except json.JSONDecodeError as e:
print(f"Failed to parse JSON: {url}, error: {e}")
break
li = res_dic.get('contents', [])
if len(li) == 0:
break
for item in li:
soup = BeautifulSoup(item, 'html.parser')
a_tags = soup.select("div.info_group a")
if len(a_tags) == 2:
news_data = get_news_item(a_tags[1]['href'])
if news_data:
ret.append(news_data)
page += 1
df = pd.DataFrame(ret, columns=["title", "media", "date", "content", "url"])
if to_csv:
df.to_csv(f"{keyword}_{startdate.replace('.','')}_{enddate.replace('.','')}.csv", index=False)
return df- 주어진 키워드와 날짜 범위에 해당하는 네이버 뉴스 기사를 수집하여 데이터프레임에 저장하고, 필요시 CSV 파일로 저장합니다.
- 작동 방식:
- 날짜 범위 설정: pd.date_range를 사용해 startdate부터 enddate까지의 날짜 범위를 생성합니다.
- 페이지 순회:
- 각 날짜에 대해 뉴스 목록 페이지를 순회합니다. 페이지마다 시작 인덱스를 계산하고, 이를 포함한 URL을 생성합니다.
- HTTP 요청: requests.get으로 URL에 대해 GET 요청을 보내고, raise_for_status()로 요청이 성공했는지 확인합니다.
- JSON 파싱: json.loads를 사용해 서버 응답을 JSON 형식으로 파싱합니다.
- 뉴스 목록 추출: JSON 데이터에서 contents 키를 통해 뉴스 목록을 가져옵니다.
- 뉴스 목록이 비어 있으면 해당 날짜의 처리 루프를 종료합니다.
- 각 뉴스 항목에 대해 HTML을 파싱하고, div.info_group a에서 두 번째 링크(기사 링크)를 선택해 뉴스 URL을 추출합니다.
- 추출한 URL을 get_news_item 함수로 처리하여 데이터를 수집합니다.
- 다음 페이지로 이동하기 위해 page를 증가시킵니다.
- 데이터 저장: 수집된 데이터를 pandas 데이터프레임에 저장합니다. to_csv=True인 경우, 결과를 CSV 파일로 저장합니다.
5. 함수 호출
get_naver_news("청년취업사관학교", "2024.01.01", "2024.07.31", to_csv=True)- get_naver_news 함수를 실행하여 "청년취업사관학교"라는 키워드를 포함한 뉴스 기사를 2024년 1월 1일부터 2024년 7월 31일까지 수집하고, 결과를 CSV 파일로 저장합니다.
'+ 개발' 카테고리의 다른 글
| Streamlit으로 데이터 분석 및 시각화 (0) | 2024.09.02 |
|---|---|
| 논문 리뷰(#텍스트 마이닝 #뉴스 분석 #금융 시장 변동성)_Gen.AI (6) | 2024.09.01 |
| 논문 리뷰(#텍스트 마이닝 #금통위 의사록 분석)_Gen.AI (3) | 2024.08.30 |
| 블로그 크롤링(#네이버 블로그)_코드 설명 (2) | 2024.08.30 |
| Pandas로 데이터 분석하기 (0) | 2024.08.29 |