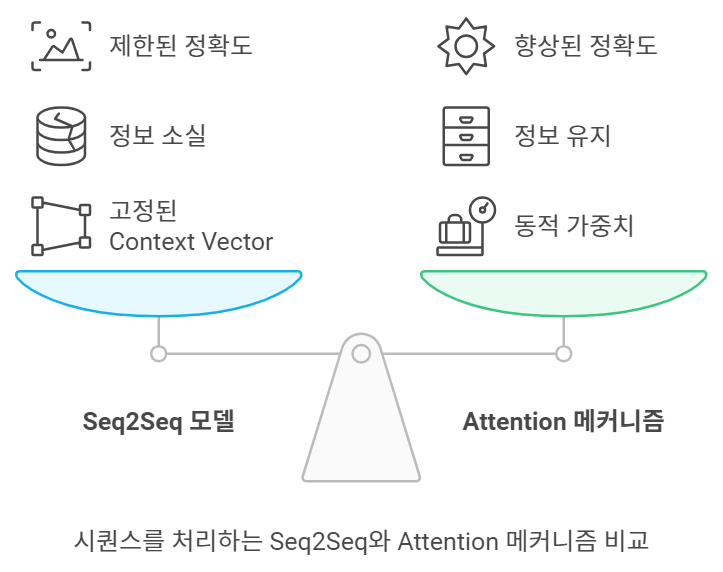
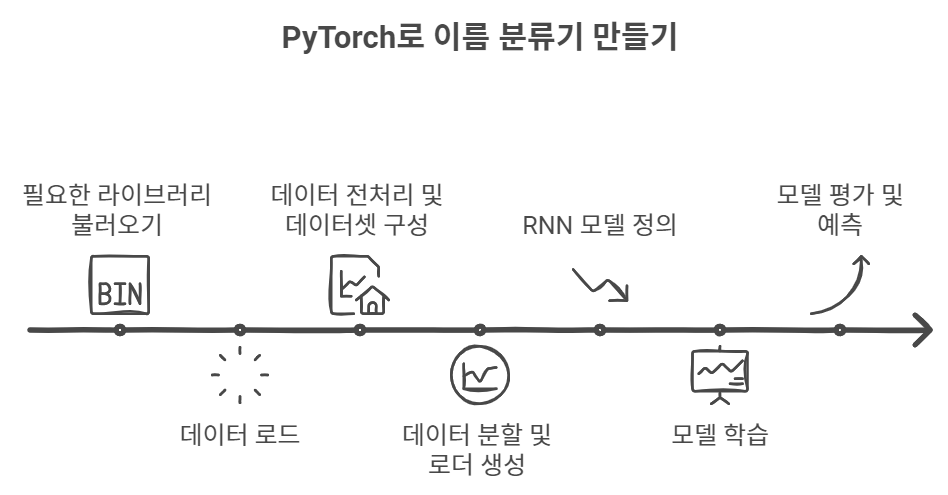
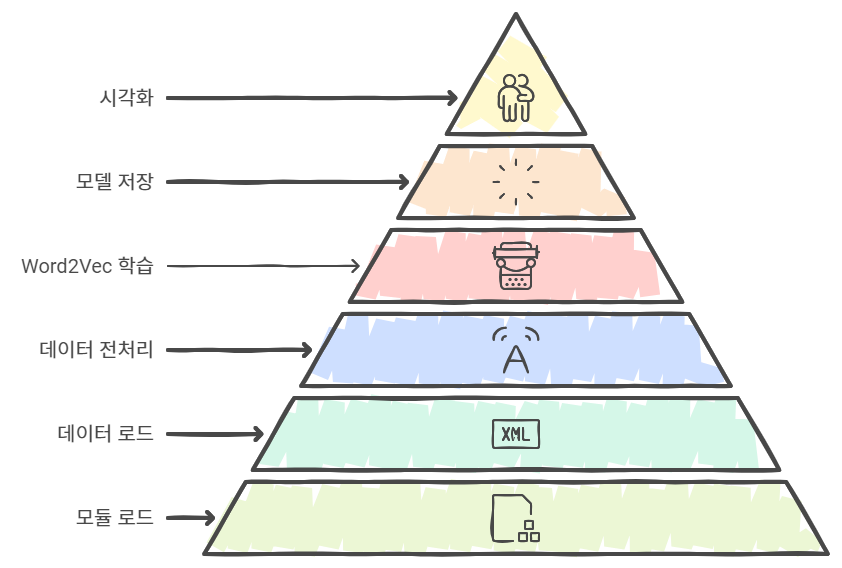
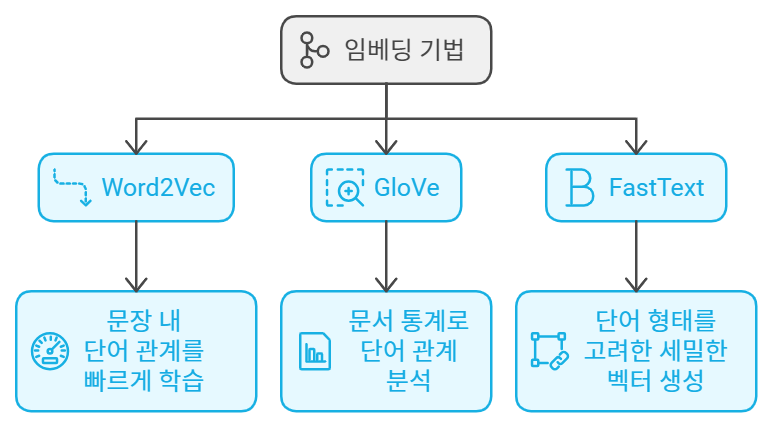
수업 내용 리마인드 및 아카이빙 목적의 업로드 오늘은 LangChain을 활용한 Few-Shot Learning과 다양한 Output Parser를 소개하려고 합니다. LangChain은 대화형 AI의 성능을 크게 향상시킬 수 있는 강력한 도구인데요, 특히 자연어 처리와 관련된 작업에서 매우 유용하게 활용될 수 있습니다. 이번 글에서는 Few-Shot Learning, 예제 선택기(ExampleSelector), 그리고 다양한 Output Parser의 사용법을 단계별로 설명드릴게요. 이를 통해 더욱 똑똑한 AI 응답을 만들어낼 수 있습니다! 1. FewShotPromptTemplate을 활용한 학습 개선LangChain의 FewShotPromptTemplate은 AI 모델에게 몇 가지 예제를 제공하여 ..