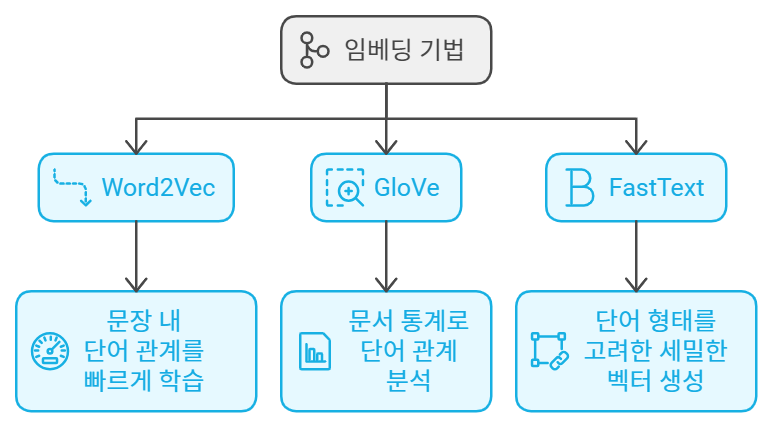
수업 내용 리마인드 및 아카이빙 목적의 업로드 Transformer 모델은 최근 자연어 처리(NLP)와 컴퓨터 비전 분야에서 가장 주목받는 딥러닝 기술 중 하나입니다. 기존의 순환신경망(RNN) 기반 모델들이 가진 여러 한계를 극복하며, 빠르고 정확한 성능을 보여주고 있습니다. 이 글에서는 Transformer 모델의 핵심 개념, 작동 방식, 그리고 그 장점을 자세히 알아보겠습니다. 1. Transformer란?Transformer는 RNN이나 LSTM과 달리 입력 시퀀스를 순차적으로 처리하지 않고, 병렬 처리를 통해 데이터를 학습하는 모델입니다. 특히 Self-Attention 메커니즘을 도입하여 시퀀스 내 모든 단어 간의 상호작용을 동시에 계산합니다. 이 방식은 RNN의 단점인 장기 의존성 문제를 해..