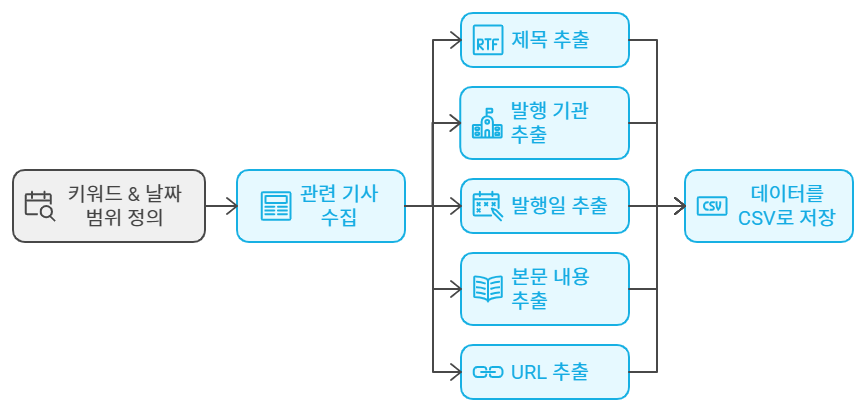
수업 내용 리마인드 및 아카이빙 목적의 업로드Q. 네이버 뉴스에서 '특정 키워드(청년취업사관학교)'와 '날짜 범위(20240101~20240731)'에 해당하는 게시물들을 자동으로 수집하고, 각 게시물의 "제목", "발행기관", "작성일", "본문 내용", "URL"을 추출하여 CSV 파일로 저장하는 코드를 작성하세요.https://search.naver.com/search.naver?where=news&query=%EC%B2%AD%EB%85%84%EC%B7%A8%EC%97%85%EC%82%AC%EA%B4%80%ED%95%99%EA%B5%90&sm=tab_opt&sort=1&photo=0&field=0&pd=3&ds=2024.01.01&de=2024.07.31&docid=&related=0&mynews=..