- 수업 내용 리마인드 및 아카이빙 목적의 업로드
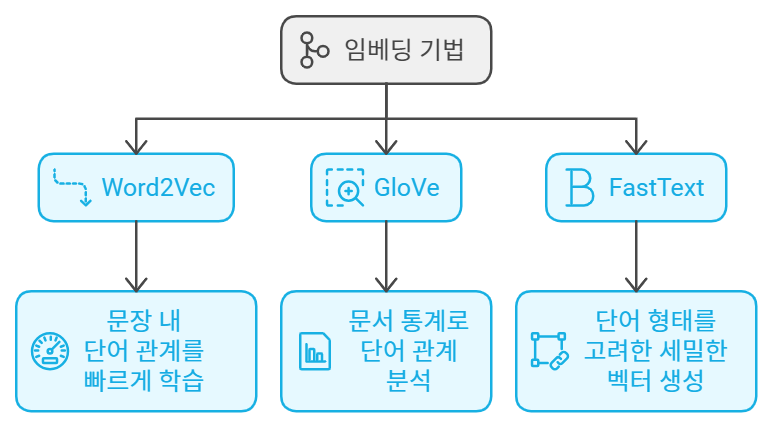
자연어 처리는 말 그대로 컴퓨터가 사람의 언어를 이해하고 처리할 수 있도록 도와주는 분야입니다. 그중에서 단어를 숫자로 변환하여 벡터로 표현하는 방법을 임베딩(Embedding)이라고 해요. 오늘은 그 대표적인 기법들인 Word2Vec, GloVe, 그리고 FastText를 차근차근 알아보려고 합니다.
1. Word2Vec – 단어와 단어 사이의 관계를 학습하자!
Word2Vec은 단어를 벡터로 표현하는 대표적인 임베딩 기법이에요. 이 방법은 단순히 단어를 숫자로 바꾸는 것에서 끝나는 게 아니라, 단어 사이의 관계까지 고려해서 단어 벡터를 만듭니다.
1) Embedding과 Vectorization의 차이
먼저 Vectorization은 단어를 수치로 변환하는 과정이에요. 하지만 단순한 변환은 단어의 유사성이나 관계를 반영하지 못한다는 단점이 있어요. 반면 Embedding은 주변 단어들과의 관계까지 고려해서 벡터를 만듭니다. 즉, 단어가 문장에서 어떻게 쓰이는지에 따라 유의미한 벡터가 생성되는 거죠.
2) Word2Vec의 핵심 아이디어
Word2Vec의 기본 원리는 간단해요. "같은 문장에서 자주 등장하는 단어들은 서로 관련이 있을 것이다." 이 아이디어를 바탕으로 특정 단어의 주변 단어를 보고 그 단어를 예측하는 방식으로 벡터를 학습합니다.
- CBOW: 주변 단어들을 보고 중심 단어를 예측하는 방식
- Skip-gram: 중심 단어로 주변 단어를 예측하는 방식
3) Word2Vec 학습 과정
Word2Vec 모델은 크게 세 단계로 학습이 이루어집니다:
- 입력층(Input Layer): 중심 단어를 원-핫 벡터로 입력
- 은닉층(Hidden Layer): 가중치 행렬을 통해 임베딩 벡터를 계산
- 출력층(Output Layer): 가중치 행렬과 Softmax 함수를 통해 단어 집합의 확률 분포를 예측
Word2Vec의 학습 과정에서 중요한 것은, 단어 간의 관계를 반영하는 벡터를 생성하는 것이죠.
2. GloVe – Word2Vec의 한계를 넘어서!
GloVe는 Word2Vec의 한계를 극복하기 위해 나온 방법이에요. Word2Vec은 단어의 등장 빈도와 주변 단어들만을 고려하는데, 이 방식은 전체 문서의 통계적 정보를 충분히 반영하지 못하는 문제가 있어요.
1) GloVe의 기본 개념
GloVe는 단어와 단어의 동시 등장 확률(Co-occurrence Probability)을 이용해서 벡터를 학습해요. 즉, 문서 전체에서 두 단어가 얼마나 자주 함께 등장하는지를 기반으로 벡터를 만들죠. Word2Vec은 단어의 관계를 문장 내에서만 파악하지만, GloVe는 전역적인 통계 정보를 활용해서 단어 사이의 더 넓은 관계를 학습할 수 있어요.
2) GloVe의 작동 원리
GloVe의 핵심은 동시 발생 행렬(Co-occurrence Matrix)이에요. 이 행렬을 통해 각 단어가 전체 문서에서 얼마나 자주 함께 등장하는지를 계산하고, 그 정보를 바탕으로 단어 벡터를 학습합니다. 예를 들어, "배"라는 단어가 "타다"와 함께 자주 나오면 그 문맥에서 '타는 배'를 의미한다고 학습하는 방식이죠.
GloVe는 Word2Vec과 유사한 결과를 보이지만, 문서 전체의 통계 정보를 반영하는 점에서 차이가 있습니다.
3. FastText – 더 세밀한 단어 표현을 위한 임베딩
FastText는 페이스북(메타)에서 개발한 임베딩 기법이에요. Word2Vec과 GloVe 모두 단어를 고유한 벡터로 학습하는 반면, FastText는 단어의 형태소를 고려해서 벡터를 만듭니다.
1) FastText의 특징
FastText는 단어를 작은 n-gram 단위로 쪼개어 학습합니다. 예를 들어, "running"이라는 단어를 "run", "ing" 등의 n-gram으로 나누어 학습하는 거죠. 이렇게 하면 형태소가 풍부한 언어(예: 터키어, 핀란드어)에서 단어 간의 관계를 더 잘 반영할 수 있어요.
2) FastText의 장점
FastText는 단어를 n-gram으로 나누어 학습하기 때문에, 이전에 학습하지 않은 새로운 단어가 나와도 그 단어의 벡터를 유추할 수 있는 장점이 있어요. 단어 벡터를 더 세밀하게 표현할 수 있는 방법인 거죠.
임베딩 기법, 어떻게 활용할까?
지금까지 Word2Vec, GloVe, 그리고 FastText에 대해 알아봤어요. 이 세 가지 기법은 자연어 처리에서 단어 간의 관계를 분석하고, 문서 내에서 의미를 추출하는 데 큰 도움을 줍니다.
- Word2Vec은 문장 내 단어들의 관계를 빠르게 학습하는 데 유용하고,
- GloVe는 전체 문서의 통계 정보를 반영해 단어 간 관계를 더 깊이 분석할 수 있으며,
- FastText는 단어의 세부적인 형태까지 고려해서 보다 세밀한 벡터를 생성할 수 있답니다.
'+ 개발' 카테고리의 다른 글
| 머신러닝(Machine Learning) 입문 (6) | 2024.09.17 |
|---|---|
| Word2Vec 모델 만들기 (7) | 2024.09.16 |
| 뉴스 데이터 LDA 분석(ft. Gensim & Scikit-learn) (11) | 2024.09.14 |
| 뉴스 데이터 LSA 분석(ft. Numpy & Scikit-learn) (1) | 2024.09.13 |
| 토픽 모델링(Topic Modeling)의 이해와 활용 (0) | 2024.09.12 |