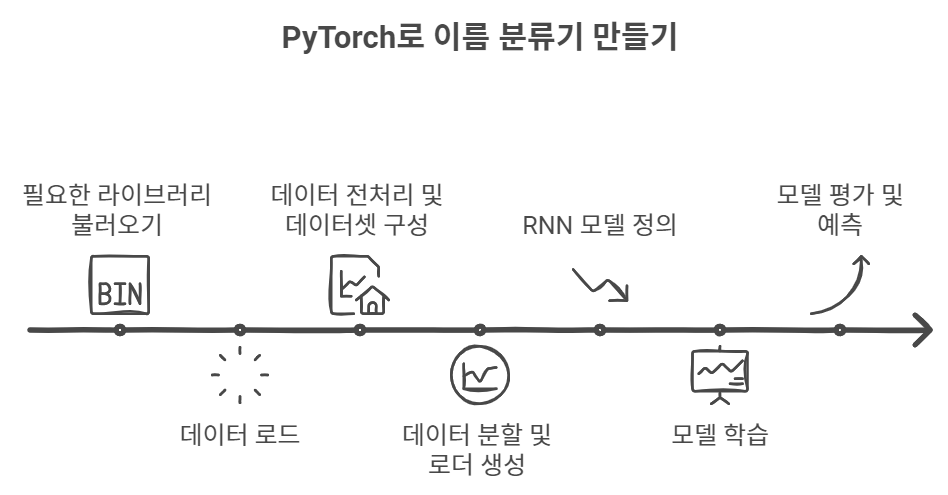
수업 내용 리마인드 및 아카이빙 목적의 업로드 이번 글에서는 PyTorch를 활용해 이름 분류기를 만들어 볼 거예요. 이 실습에서는 이름 데이터를 사용해 특정 언어를 예측하는 모델을 만들어 보고, 학습한 후 모델의 성능을 평가해보겠습니다. 과정을 차근차근 따라가면 어렵지 않게 이해할 수 있으니, 함께 진행해봐요.1. 필요한 라이브러리 불러오기우선 실습에 필요한 라이브러리들을 불러올게요. GPU를 사용 가능한 경우, GPU를 사용해 학습 속도를 높일 수 있습니다.import torchimport torch.nn as nnimport torch.optim as optimfrom torch.nn.utils.rnn import pad_sequencefrom torch.utils.data import Datase..